

























































基于 python 对文本做分词、生成词云图
为何选 python
Python 是一种易于学习又功能强大的编程语言。它优雅的语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本,以及快速开发应用的理想语言。此外,Python 具有丰富强大的功能库,可以直接加以引用,省却很多工作量。
大致思路
假如已经获得文本,只需进行以下步骤即可:
- 对指定文本,基于
jieba进行分词,得到词汇列表; - 对所得词汇列表进行计数,获得高频词汇列表(过滤排除、由高到低排序);
- 根据排序后的高频词汇列表,取前 N(100)条,拼接为字符串;
- 依据拼接后字符串,基于 wordcloud、image 功能库生成词云图;
具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | # gen-wordcloud-img.py import jieba import wordcloud import PIL.Image as image import numpy as np relative_path = './wordcloud/' target_path = 'target.txt' defget_jieba_words(): content_str = open(relative_path + target_path, 'r', encoding='utf-8').read() return jieba.lcut(content_str) defget_high_frequency_word(param_list): exclude_words_list = ['我们', '你们', '可以'] counts_dict = {} for word in param_list: if len(word) == 1: continue else: is_word_exist = False for ex_word in exclude_words_list: if ex_word in word: is_word_exist = True ifnot is_word_exist: ifnot word.isdigit(): count = counts_dict.get(word, 0) + 1 counts_dict[word] = count return sorted(counts_dict.items(), key=lambda x: x[1], reverse=True) defget_cloud_words(param_list): result_str = '' for item in param_list[0:100]: occur_count = item[1] for _ in range(occur_count): result_str = result_str + ' ' + item[0] return result_str defgen_and_save_wordcloud_img(param_str): mask = np.array(image.open(relative_path + "style.jpg")) wc = wordcloud.WordCloud(width=1430, height=646, background_color="rgba(255, 255, 255, 0)", mode="RGBA", font_path=relative_path + 'MSYH.TTC', collocations=False, max_words=100, mask=mask) # 调用词云对象的 generate 方法,将文本传入 wc.generate(param_str) # 将生成的词云以图片文件格式,保存在当前目录 wc.to_file(relative_path + 'output-result.png') jieba_words_list = get_jieba_words() print('所获得 jieba 分词个数为:', len(jieba_words_list)) high_frequency_word_list = get_high_frequency_word(jieba_words_list) print('所得高频分词前 100 分别是:', high_frequency_word_list[0:100]) cloud_words_str = get_cloud_words(high_frequency_word_list) gen_and_save_wordcloud_img(cloud_words_str) print('已成功生成「词云图」并保存在当前目录.') |
以上,便是全部代码实现;倘若真正使用,请参考 play-with-python @wordcloud。这是因为在生成词云图,支持自定义背景图片、以及宽高、字体、背景色等;由此用到了指定的图片和字体。
如何使用
此代码片段基于 python3 运行,如果本机器 python 环境默认为 python3,则可以直接基于 pip、python 来运行命令。在个人本机上,一些 Web 开发工具仍依赖于 python2.6 ,也就未将 python3 修改默认环境。
安装依赖
1 | pip3 install wordcloud jieba numpy |
一键调用
1 2 3 | python3 gen-wordcloud-img.py # OR python gen-wordcloud-img.py |
具体效果
个人很喜欢王小波先生、路遥先生。对王小波的杂文《工作与人生》,以及路遥先生的《早晨从中午开始》,基于这段脚本做下处理,来看下具体效果。
王小波《工作与人生》前 100 高频词汇词云图:
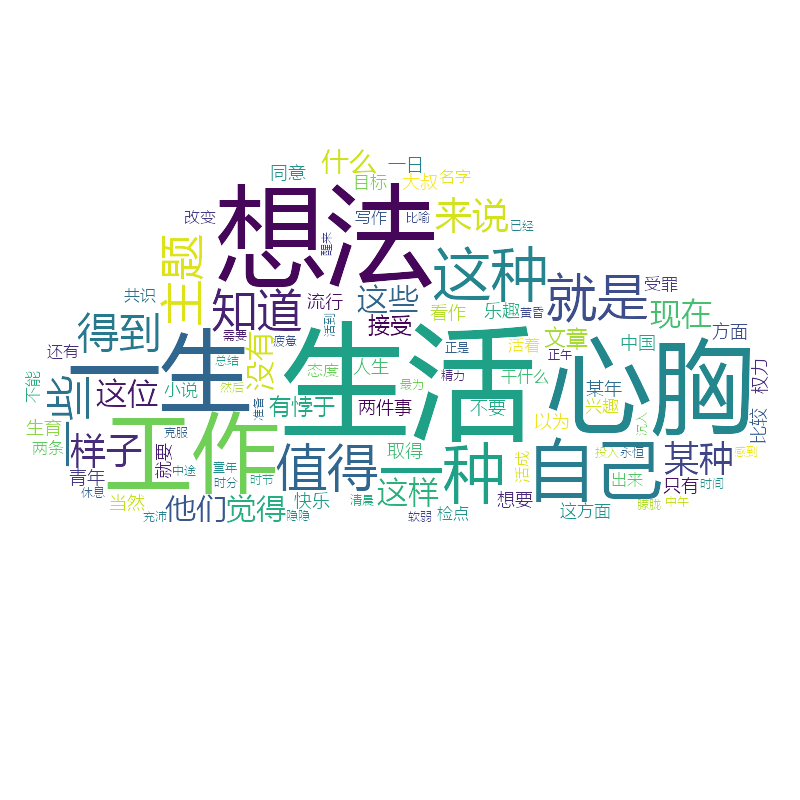
路遥先生《早晨从中午开始》前 100 高频词汇词云图:
 扫描关注公众号
扫描关注公众号