

























































信息收集之利用Python批量判断CDN
简介
在平时的安全测试中,信息收集是非常重要的一部分,信息收集之前少不了最重要的一步,就是判断网站是否使用了CDN。在测试过程中,如果目标使用了CDN 服务,将会影响到后续的安全测试过程。
方法
判断CDN的方法有很多种,在这里主要来讲解用nslookup判断并实现批量判断的目的。
使用nslookup,如果目标有CDN服务的话,那么将会返回多个IP地址(>=2个)。
nsllokup www.xxxx.com

可以清楚的看到该域名返回了两个地址,可以判断该域名使用了CDN服务。
我们的目的就是用python来判断返回ip的条目,在该图中,如果ip条目>=3条,那么就存在CDN
代码实现
主要用到的库为os,re,主要方法为正则表达式。
这里我们首先看一下如何提取出来nslookup里面的ip地址
\d\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}这个表达式的意思是提取出以x.x.x.x形式的内容
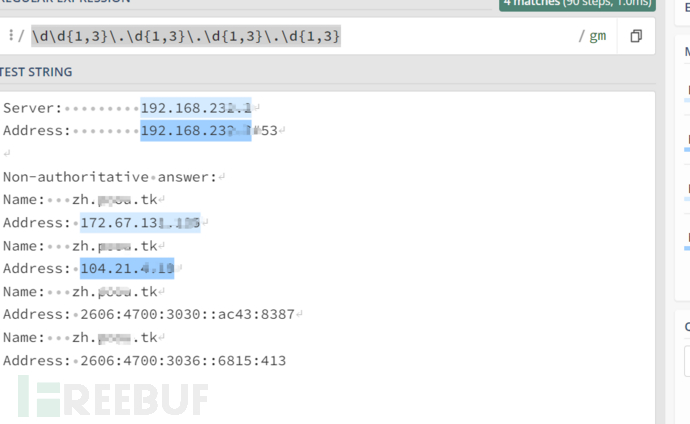
可以看到在有CDN的情况下ip条目为至少四条
再来看看没有CDN的情况
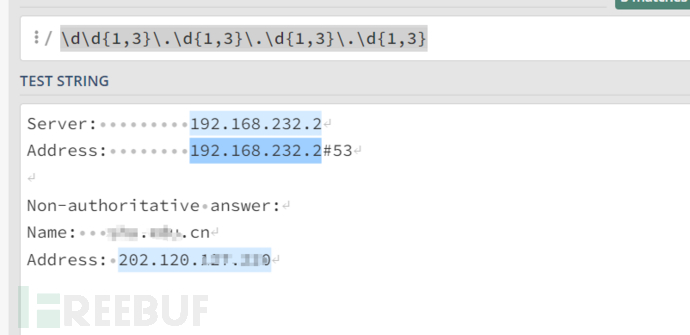
在没有CDN的情况下ip条目为三条
再来看一下不存在ip地址的情况
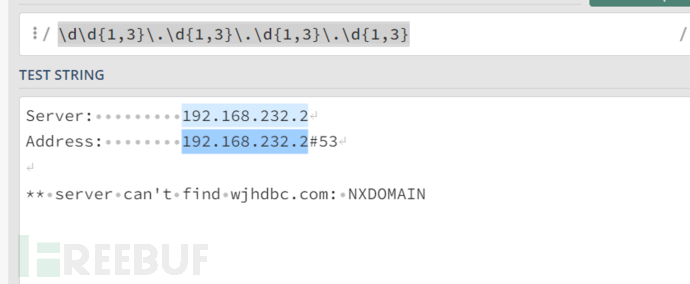
不存在时,ip条目为两条,综上所述,基本的代码原理也就出来了。
简易代码如下:(liunx上运行)
import os
import re
domain=open("./url.txt")
#判断CDN
for domains in domain:
domains = domains.strip("\n")
result=os.popen("nslookup " + domains).read()
results=re.findall(r'\d\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}',result,re.S)
if len(results)==2:
print(domains + " 没有ip地址")
if len(results)==3:
print(domains + " 不存在CDN")
print(results[-1])
if len(results)>3:
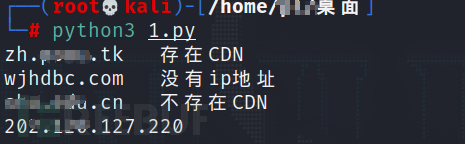
print(domains + " 存在CDN")代码实现的效果图
 扫描关注公众号
扫描关注公众号