

























































RE与算法 | 单向散列算法(哈希算法)
前言:什么是单项散列算法?
可能单独讲单向散列算法,师傅们会感觉比较陌生,那是因为它有一个更深入人心的别名:Hash(哈希算法)。
哈希(Hash)算法是一种将任意长度信息压缩到某一固定长度的函数,且过程不可逆。且由于其过程不可逆的特点,被广泛应用于:数字签名,验证文件完整性,文件的起源检测等方面。同样由于不可逆性,软件只能使用hash函数作为加密的一个中间步骤。比如对用户名进行Hash变换,在对这个结果进行可逆的加密变换,得到变换结果为注册码。
常见的单向散列算法:MD5 SHA系列 RIPE-MD HAVAL N-Hash
本篇文章研究的单向散列算法:md5 SHA系列 SM3国密算法(国家密码局)
MD5
md5是一种哈希算法,常用来保证信息的完整性。由于其不可逆性,其典型应用是对一段信息(Message)产生信息摘要(Message-Digest),以防止被篡改。例如数字签名。
加密过程
0x01 填充
在计算机中,数据存储都是二进制存储的,所以任意一个文件都是些二进制。
每个文件(消息)的大小(长短)都不一样,所以在计算MD5值之前,要将这些文件(消息)用特定内容填充到指定的情况为止。(这里的大小长度是指字节数)
过程如下:
1.先判断文件(消息)的大小(长度) mod 512 == 448 mod 512 ,就是大小(长度)对512求余等于448。(这里的512、448是“位”为单位,转成“字节”就是64、56,即mod 64 == 56 mod 64)
2.如果大小(长度)满足 mod 512 == 448 mod 512,就在文件(消息)的末尾处添加64位(8字节)的值,值的内容是原消息的长度(以位为单位)
3.如果大小(长度)不满足要求,就执行以下操作: (1)填充1个1(这里是以位为单位,如果以字节为单位就是填充0x80) (2)填充0,直到满足满足过程的第一步。
填充举例:
消息内容为五位数据,第一个填充的就是0x80(1位)
67 6E 75 62 64 80 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 28 00 00 00 00 00 00 00
0x02 初始化变量
用四个变量来计算消息摘要,这里的abcd都是32位寄存器
A = 0x01234567
B = 0x89ABCDEF
C = 0xFEDCBA89
D = 0x76543210
为了保证ABCD四个值在内存中的显示为上面的情况,需要调整数字的位置,故实际情况是:
A = 0x67452301;
B = 0xEFCDAB89;
C = 0x98BADCFE;
D = 0x10325476;
0x03 加密信息:
经过信息填充后,填充后的信息长度肯定是512位(64字节)的倍数,也就是说每512位(64字节)为1段可以分成n段,(n大于等于1),对于每一段信息(512位,64字节)又划分成16小段(每段32位,4个字节,用M表示)每一小段的信息,都会经过下列的运算处理,共四种函数:
对于每一段信息,都会经过下列的运算处理,共4种函数:FF/GG/HH/II
void md5::FF(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD mj,DWORD s,DWORD ti){
DWORD temp = F(b,c,d) + a + mj + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::GG(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD mj,DWORD s,DWORD ti){
DWORD temp = G(b,c,d) + a + mj + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::HH(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD mj,DWORD s,DWORD ti){
DWORD temp = H(b,c,d) + a + mj + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::II(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD mj,DWORD s,DWORD ti){
DWORD temp = I(b,c,d) + a + mj + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}被四大函数调用的 F G H I 四个函数是
DWORD md5::F(DWORD X,DWORD Y,DWORD Z){
return (X&Y)|((~X)&Z);
}
DWORD md5::G(DWORD X,DWORD Y,DWORD Z){
return (X&Z)|(Y&(~Z));
}
DWORD md5::H(DWORD X,DWORD Y,DWORD Z){
return X^Y^Z;
}
DWORD md5::I(DWORD X,DWORD Y,DWORD Z){
return Y^(X|(~Z));
}接下来是执行过程,附上一段伪代码便于理解
for(int j=0;j<16;j+=4){ //每次增加4
FF(A,B,C,D,M[m[j]],s[j],T[j]);
FF(D,A,B,C,M[m[j+1]],s[j+1],T[j+1]);
FF(C,D,A,B,M[m[j+2]],s[j+2],T[j+2]);
FF(B,C,D,A,M[m[j+3]],s[j+3],T[j+3]);
}
for(;j<32;j+=4){
GG(A,B,C,D,M[m[j]],s[j],T[j]);
GG(D,A,B,C,M[m[j+1]],s[j+1],T[j+1]);
GG(C,D,A,B,M[m[j+2]],s[j+2],T[j+2]);
GG(B,C,D,A,M[m[j+3]],s[j+3],T[j+3]);
}
//HH、II也类似,每种函数执行16次(1轮4次,4轮16次)后再执行下一种函数 j的值向后类推解释一下上述伪代码:
首先是变量:
M是上面每一段的16个小段了,其中m[j]表示每次函数处理的小段都不同,按照一定的顺序来处理每个小段,其中的顺序就在m中保存了。 s是循环左移的位数,也有一定顺序。 T是常数,共64个,意味着64次的函数调用都是用不同的数值。
然后是过程:
对于第一段消息(前512位(64个字节))传入的a,b,c,d的值是上面初始化的ABCD。 第一段消息处理完后(即4个函数各执行了16次之后),得到新的a,b,c,d的值,将它们分别加上原来a,b,c,d的值(即计算前的值),作为下一段消息(第2个512位(64个字节))的初始a,b,c,d的值。
当每段消息(512位,64个字节)都处理完之后,得到的a,b,c,d的值,按照地址的顺序从低到高打印对应的值,就是所求的MD5值。
逆向实战中的MD5识别
主要分为三部分:函数识别,特征值识别,特征运算识别
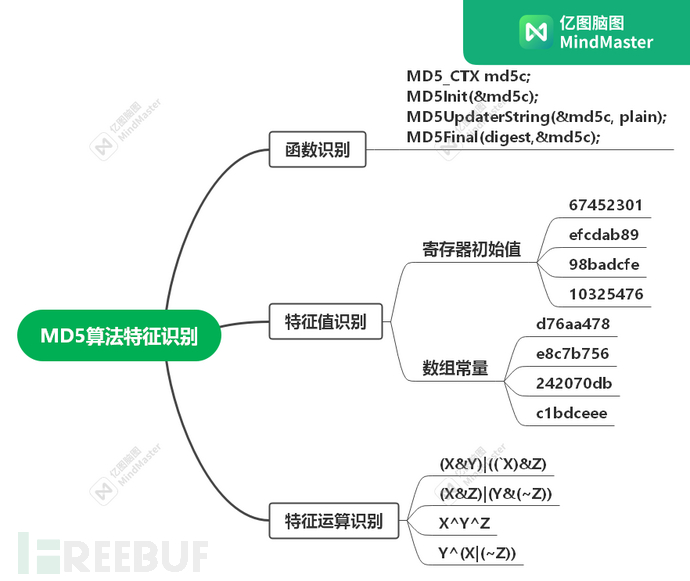
MD5的常见动调方法
在MD5Update()上下个断点,观察输入输出的参数。可以用下面参数快速测试下是不是MD5算法:
MD5("") = d41d8cd98f00b204e9800998ecf8427e
MD5("a") = 0cc175b9c0f1b6a831c399e269772661
MD5("abc") = 900150983cd24fb0d6963f7d28e17f72java中的MD5
在java中实现MD5是很简单的,在包java.security有个类MessageDigest。官方文档如下
MessageDigest 类为应用程序提供信息摘要算法的功能,如 MD5 或 SHA 算法。信息摘要是安全的单向哈希函数,它接收任意大小的数据,输出固定长度的哈希值。
代码如下:
import java.security.MessageDigest;
public class MyMD5 {
static char[] hex = {'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F'};
public static void main(String[] args) {
try{
MessageDigest md5 = MessageDigest.getInstance("MD5");//申明使用MD5算法
md5.update("a".getBytes());//
System.out.println("md5(a)="+byte2str(md5.digest()));
md5.update("a".getBytes());
md5.update("bc".getBytes());
System.out.println("md5(abc)="+byte2str(md5.digest()));
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 将字节数组转换成十六进制字符串
* @param bytes
* @return
*/
private static String byte2str(byte []bytes){
int len = bytes.length;
StringBuffer result = new StringBuffer();
for (int i = 0; i < len; i++) {
byte byte0 = bytes[i];
result.append(hex[byte0 >>> 4 & 0xf]);
result.append(hex[byte0 & 0xf]);
}
return result.toString();
}
}
python中的MD5
python中 有专门实现各种hash算法的库 hashlib1
import hashlib1
m = hashlib.md5()
m.update("123".encode("utf-8"))
result = m.hexdigest() # m.digest()返回的是类似于上面未经过sprintf格式化之前的样子,16进制的格式
print (result)
<实战> md5 crackme破解练习
动态调试
本实例来自《加密与解密》的MD5KeyGenMe。
首先使用peid进行查壳,使用插件发现该文件中含有MD5常数,猜测可能使用了MD5算法
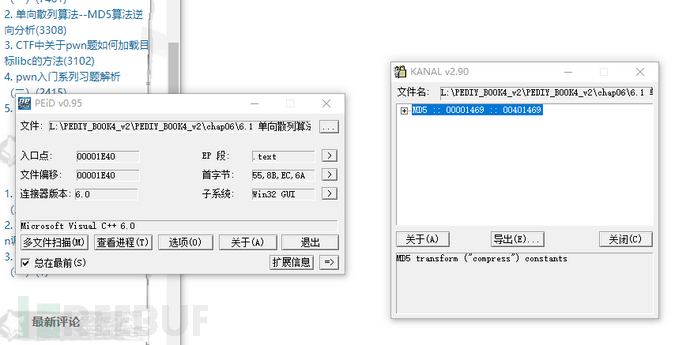
使用od打开,在命令行输入 bpx GetDIgTextA,给所有该函数调用下断点后F9把程序跑起来
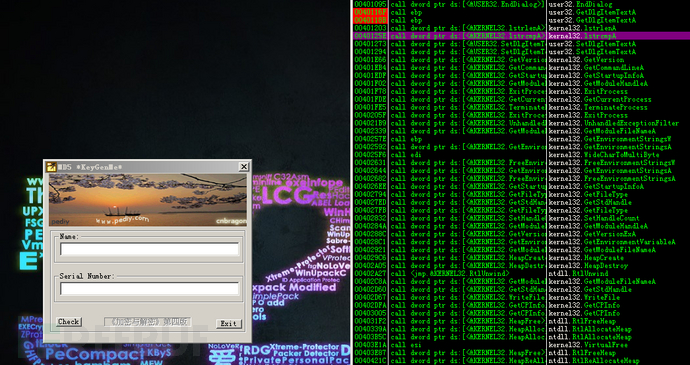
在弹出的界面中输入Name:xingzherufeng 和Serial Number:0123456789ABCDEF,单击“Check”按钮,程序中断在第一个下断处。
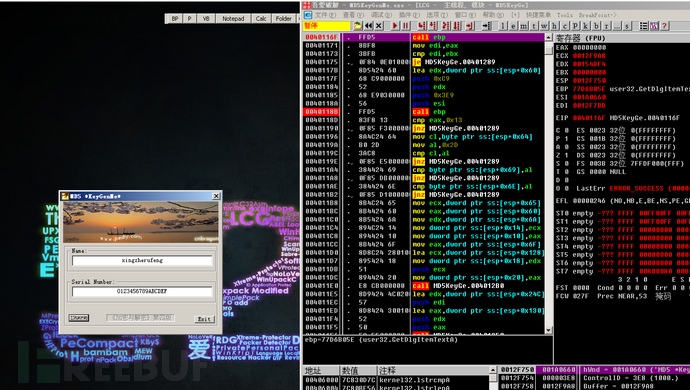
F8单步调试(不步入),观察寄存器窗口各个寄存器的变化可以读出以下有效数据
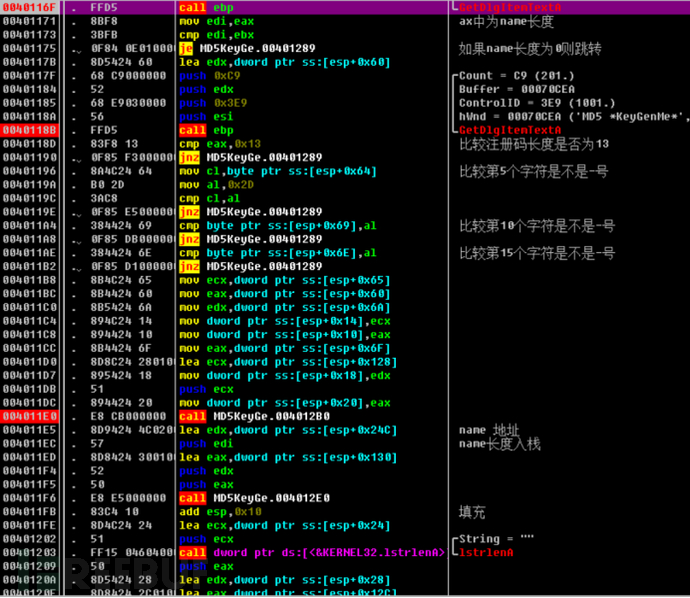
在00401190处的条件判断,判断输入的密钥是否长度为13,我们一开始输入的密钥长度不符,因此需要修改判断,由于上一条语句cmp eax,0x13得知相等时标志位ZF=1(ZF=0表示结果不为0,ZF=1表示结果为0),而此时JNZ是当结果不为0时跳转,也就是长度不想等时跳转,因此我们需要修改符号为ZF=1来绕过。
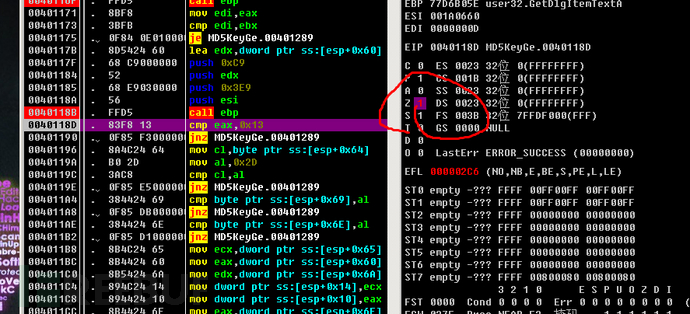
接着F8单步到004011E0发现有一个Call跳转,F7进入看一看,发现4个常数,很明显这是在进行MD5初始化。
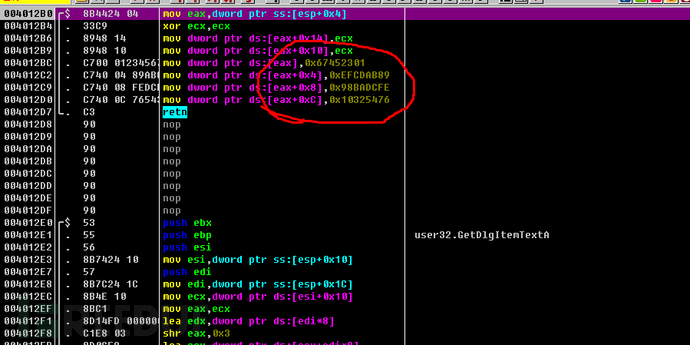
继续单步,遇到Call进入观察,会发现在00401400这个段中(跳转来自00401338)疑似存在MD5转换代码
从0040142B开始发现由与、或、非、左移。以及常量T[i]且下面具有循环代码,由此推断这里就是MD5转化的代码所在地,也因此确定本应用使用了md5加密。
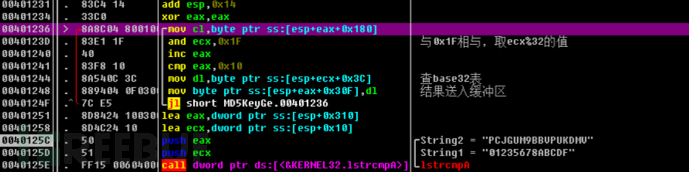
继续单步发现一个循环,循环下面出现IscmpA函数,猜测进行密钥比较。发现字符串“PCJGUM9BBVPUKDMV”与我们输入的比较,同时出现让我们猜测是否这就是正确的序列号。
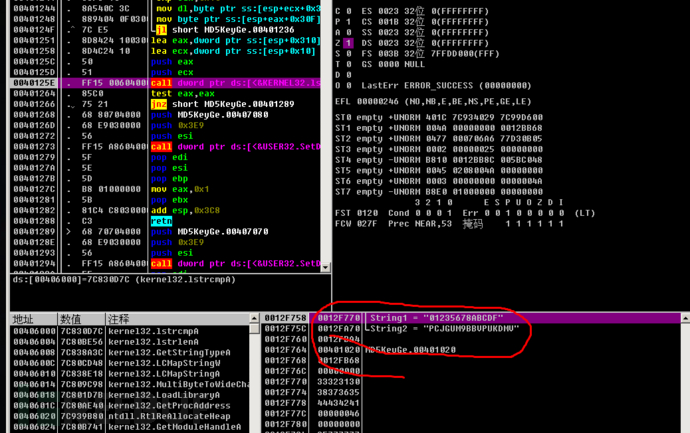
记得每4个字符用“-”隔开。成功cracked!nice
静态分析
先用和动调相同的方式 查壳。
利用ida在导入表中找到GetDlgItemTextA函数定位关键代码,两次GetDlgItemTextA函数读取的应该分别是Name和Serial Number:

跟进sub_4012B0函数发现了MD5的几个特征常量:
_DWORD *__cdecl sub_4012B0(_DWORD *a1)
{
_DWORD *result; // eax
result = a1;
a1[5] = 0;
a1[4] = 0;
*a1 = 1732584193;
a1[1] = -271733879;
a1[2] = -1732584194;
a1[3] = 271733878;
return result;
}
阅读各引用函数代码,重命名确定md5各大函数需要注意的一点是连续调用两次MD5_Update相当于把两次的输入拼接后调用一次MD5_Update的结果:
根据代码写出注册机
from hashlib import md5
name = b'pediy'
digest = md5(name + b'www.pediy.com').digest()
a2345 = '23456789ABCDEFGHJKLMNPQRSTUVWXYZ'
serial_number = ''
for b in digest:
serial_number += a2345[b % 32]
print(f'Serial Number('{name}')={serial_number[0:4]}-{serial_number[4:8]}-{serial_number[8:12]}-{serial_number[12:16]}')
SHA系列
Sha系列算法,又叫做安全散列算法,其包括 sha-1(160),sha-256,sha-384,sha-512四种,分别产生160/256/384/512位的散列值
加密过程
详解一下SHA-256,sha系列算法原理都差不多,分类不同是由于产生的输出长度不同。
SHA-256算法输入报文的最大长度不超过264Bits,输入按512Bits分组进行处理,产生的输出是应该256Bits的报文摘要。
首先我们会添加填充位,对报文进行填充使用使报文长度与448模512同余,填充的比特数范围是1-512,填充比特串的最高位1,其余位为0,就是先在报文后面加一个1(0x80),再多加一个0,直到长度满足mod512=448。 这里为什么是448呢?因为448+64=512第二步会加上一个长度64位的原始报文长度......好吧前两步处理都和md5是一样的。
第三步初始化缓存,使用一个256位的缓存来存放该散列函数的中间及最终结果,它可以表示为8个32位的寄存器。 ABCDEFGH。接着是对用户名进行循环hash处理,循环次数取决于用户输入的用户名长度,经过循环后,最后将结果存入eax指向的位置。最后输出结果,所有的512报文为分组处理完毕后对于SHA-256算法最后一个分组产生的输出便是256位的报文摘要。
循环hash具体操作:
首先通过循环的方式,将用户输入的用户名进行sha1_process 处理。然后调用sha1_hash函数对字符串进行hash运算,此处是对用户名进行循环亦或操作,异或后存入 ss:[esp+eax*1+0x40]
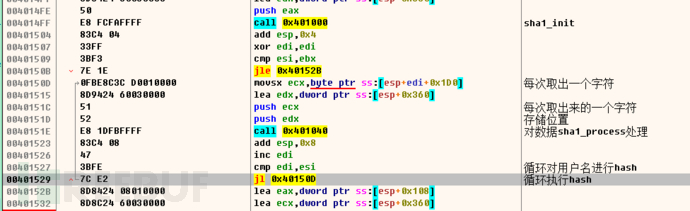

再将异或后的值,与第二个字符串进行异或操作。最后再执行一轮异或,操作结束。

逆向实战中的sha系列算法识别
以sha-1为例,其会产生160位消息摘要,在对消息处理之前,初始散列值H用5个32位双子进行初始化,可以通过识别这些双字压缩常数来确定是否是该算法。
h0=> 67452301h h1=>efcdab89h h2=>98badcfeh h3=>10325476h h4=>c3d2e1f0h
以下代码,就是标准的sha-1散列初始化标志
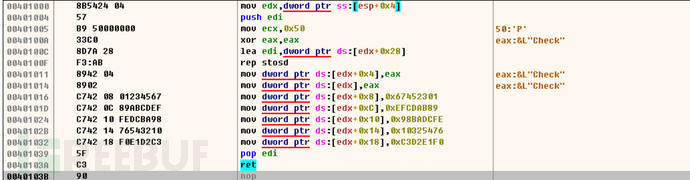
另外三种的识别特殊值如下图

<实战> md5 crackme破解练习
本实例来自《加密与解密》的SHA1KeyGenMe。
静态分析
还是采用和md5crackme一样的方法。通过定位GetDlgItemTextA函数来定位关键函数
继续跟进401000函数 发现sha1加密使用的特殊常量
int __cdecl sub_401000(_DWORD *a1)
{
int result; // eax
result = 0;
memset(a1 + 10, 0, 0x140u);
a1[1] = 0;
*a1 = 0;
a1[2] = 1732584193;
a1[3] = -271733879;
a1[4] = -1732584194;
a1[5] = 271733878;
a1[6] = -1009589776;
return result;
}
根据伪代码理解修改以下函数名
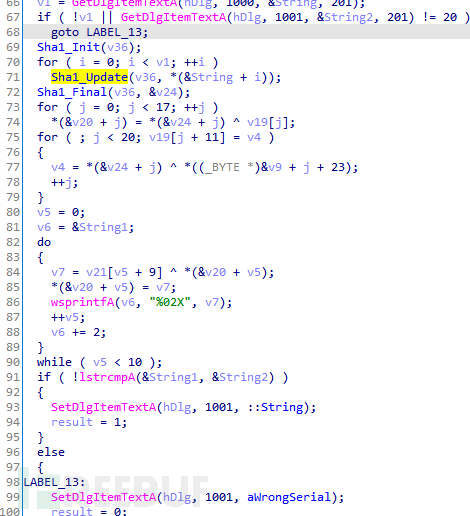
写出注册机:
from hashlib import sha1
name = b'pediy'
digest = sha1(name).digest()
aPEDIY = b'PEDIY Forum'
apediy = b'pediy.com'
key = bytearray(digest)
for i in range(11):
key[i] ^= aPEDIY[i]
for i in range(12,17):
key[i] ^= key[i - 12]
for i in range(17,20):
key[i] ^= apediy[i - 17]
serial_number = ''
for i in range(10):
serial_number += hex(key[i] ^ key[i + 10])[2:].zfill(2).upper()
print(serial_number)
得到注册码成功cracker。
 扫描关注公众号
扫描关注公众号